From Best-of-n to Ranking n: A New Approach to Collective Decision-Making in Robot Swarms
Background
As a Postdoctoral Research Associate (PDRA) at the University of Bristol, I explored how multi-agent systems can make collective decisions under greater limitations than typically considered in traditional approaches to the "best-of-n" problem in robot swarms. In our paper, published in Swarm Intelligence (2021), we introduce a novel model for collective preference learning that allows robot swarms to learn not just which option is best, but to rank all available options.
Beyond binary choices
Traditional approaches to the best-of- problem often focus on identifying only the single best option from a set of alternatives, discarding information about the remaining options. While this works for simple scenarios, real-world applications like search and rescue operations require more nuanced decision-making.
In a disaster scenario, for example, a swarm searching for casualties using the traditional approach would only identify the highest priority casualty, requiring the entire decision process to restart for each remaining one.
Our three-valued logic approach
Instead of using binary logic (option A is better/worse than option B), we developed a model using three-valued logic where robots can hold beliefs about preference relations in three states:
- True (option A is better than option B)
- False (option A is not better than option B)
- Uncertain
This enables agents to maintain and refine a complete preference ordering over all options simultaneously, rather than simply identifying which option is best.
Key findings
Our experiments showed:
Robust to Noise: The model performs well even in noisy environments where evidence might be contradictory or incorrect. When evidence is sparse and noise levels are high, preserving the transitivity of agents' beliefs improves accuracy further.
Scalable Solution: Our approach successfully scales to environments with up to options before accuracy is significantly affected in noisy environments.
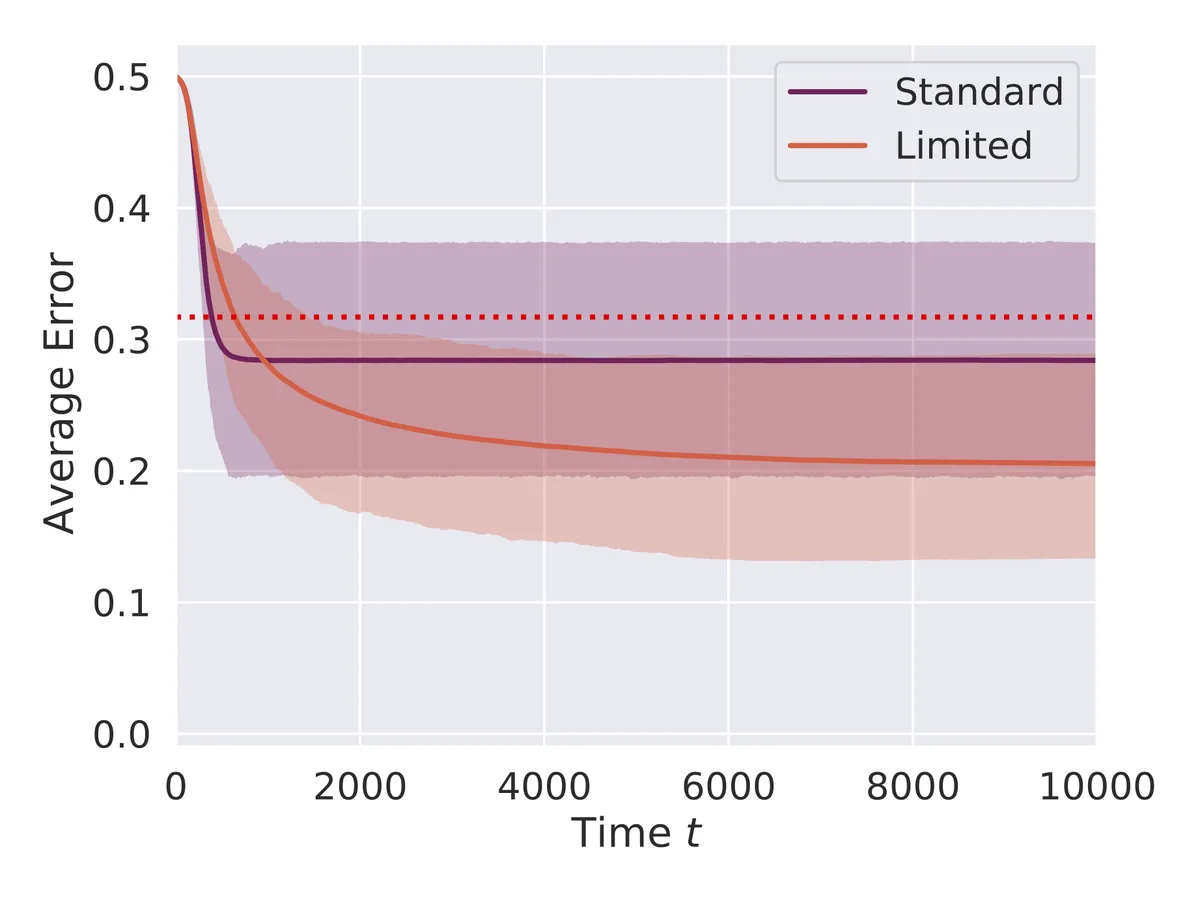
High-noise scenario
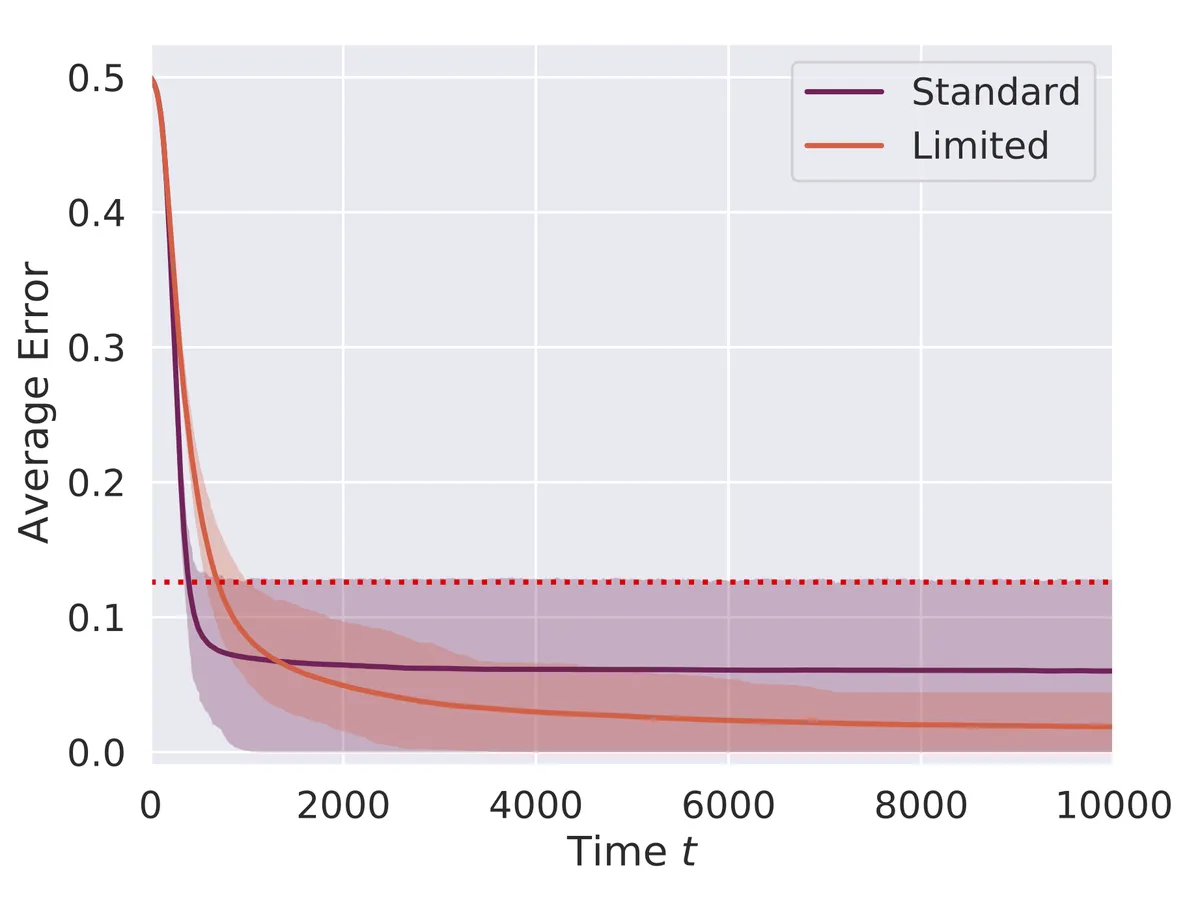
Low-noise scenario
Communication Efficiency: We developed a bandwidth-limited version allowing agents to communicate only a subset of their preference relations, which still performs well and sometimes outperforms the standard model.
Speed-Accuracy Trade-off: There's a clear trade-off between increased accuracy (by applying transitive closure operations) and computational cost, giving system designers flexibility depending on application requirements.
Why this matters
Ranking multiple options is useful in several applied swarm robotics scenarios:
- Search and rescue operations where casualties must be prioritized
- Environmental monitoring where multiple phenomena need to be tracked and ranked
- Infrastructure inspection where multiple defects must be classified by severity
Learning complete preference orderings means the swarm retains useful information after the highest-priority task is completed, since the next task is already decided.
Future research directions
Open questions include how this approach performs under physical constraints (limited communication range, limited observation capabilities) and whether the model can be adapted for dynamic environments where preferences change over time.
More detailed information about this research can be found in our paper: "Collective preference learning in the best-of- problem: From best-of-n to ranking " published in Swarm Intelligence (2021).